Multiview SAM-6D
Supervised by Jonas Hein
The Problem: One View Is Not Enough
6D object pose estimation — figuring out an object’s full 3D position and orientation from camera images — is everywhere in robotics and AR. SAM-6D is a recent method that does this in a zero-shot manner: you give it an RGB-D image and a CAD model, and it estimates poses for objects it has never seen during training. It works by first using the Segment Anything Model (SAM) to generate object proposals, then matching 3D points between the segmented scene and the CAD model through a coarse-to-fine pipeline.
The catch? It only uses a single view. In practice, occlusion hides object parts, symmetric geometries create ambiguity, and depth noise degrades accuracy. A single viewpoint simply doesn’t give you enough information in cluttered real-world scenes.
Our goal was to extend SAM-6D to leverage multiple views to improve accuracy, resolve ambiguities, and handle occlusions — all without retraining any of the original models.
Our Multi-View Pipeline
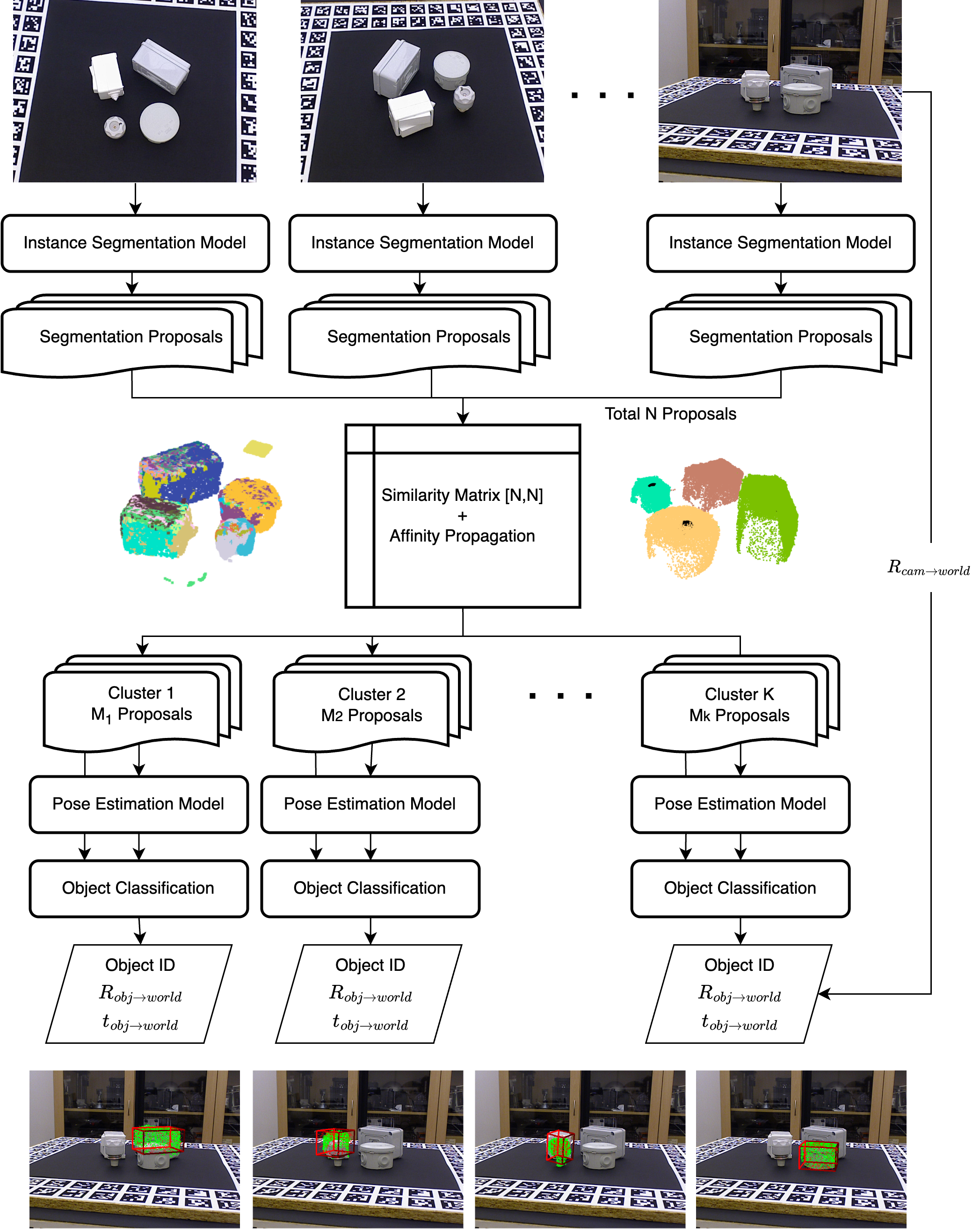
The pipeline has five stages:
1. Per-view Segmentation. Each RGB-D view is independently processed by SAM-6D’s Instance Segmentation Model (ISM) to generate object proposals — segmentation masks with associated 3D point clouds and ViT features.
2. Proposal Matching. This is where multi-view reasoning kicks in. We need to figure out which proposals across different views correspond to the same physical object. We compute a similarity score between every pair of proposals using three signals: spatial proximity of their 3D centroids, mask projection consistency (projecting one proposal’s points into another view and checking overlap), and depth consistency (verifying that projected depths agree, which helps filter out occlusions). We then apply Affinity Propagation clustering on the resulting similarity matrix. A key design choice: we only keep clusters that contain proposals from at least two views, which effectively filters out false positives that appear in only one viewpoint.
3. Multi-view Fusion. For each cluster, we transform all associated point clouds and features into a shared world coordinate frame using known camera poses, then merge them. Voxel-based downsampling keeps the fused point cloud at a manageable density.
4. Pose Estimation. The fused point cloud and features are fed into SAM-6D’s Pose Estimation Model (PEM), which performs coarse-to-fine 3D point matching against the CAD model to estimate the 6D pose.
5. Object Classification. Instead of relying solely on the ISM’s appearance-based scores (as the original SAM-6D does), we combine ISM and PEM confidence scores across all proposals in a cluster to vote on the object identity. This joint scoring leverages both visual and geometric consistency.
Results
We evaluated on the T-LESS dataset from the BOP benchmark — a particularly challenging dataset with textureless, symmetric industrial objects. Our multi-view method consistently outperformed single-view SAM-6D across all metrics:
| Metric | SAM-6D (single-view) | Ours (multi-view) |
|---|---|---|
| AR_MSPD | 46.79 | 57.36 |
| AR_MSSD | 47.71 | 57.12 |
| AR_VSD | 42.03 | 50.70 |
| mAR | 45.51 | 55.06 |
| Classification Recall | 67.62 | 77.24 |
An ablation with ground truth segmentation masks was especially revealing: our multi-view pipeline achieved 93.35 mAR (vs. 68.47 for single-view), showing that multi-view fusion amplifies the benefit of good segmentation dramatically. It also tells us that segmentation quality is still the main bottleneck — about 36% of the mAR gap between our ISM-based result (55.06) and the GT-mask result (93.35) comes from incorrect segmentation.
We also found that performance steadily improves as more views are added (tested up to 6), and that post-hoc geometric refinement methods like ICP and CPD didn’t help — likely because residual noise in the fused point clouds undermined the alignment.
What I Learned
This was my first time working with a multi-view 3D vision pipeline end-to-end, and a few things stood out.
First, the power of simple heuristics in the right place. The proposal matching stage doesn’t use any learned components — just centroid distance, mask reprojection, and depth checks — yet it’s the core enabler of the entire multi-view extension. Getting those similarity metrics and their weighting right mattered more than any architectural change.
Second, segmentation is the bottleneck, not pose estimation. The GT-mask ablation made this very clear. The PEM is already quite capable; it’s the upstream segmentation and clustering that limit overall performance. Future work on making ISM geometry-aware (using multi-view information during segmentation itself, not just after) seems like the most impactful direction.
Third, working within constraints teaches you a lot. We had limited GPU memory and couldn’t retrain any models, so every design decision had to work within SAM-6D’s existing architecture. This forced us to think carefully about where multi-view information could be injected most effectively without changing the model itself.
The code is available at github.com/oxcarxierra/SAM-6D.